Implementing a Big Data Pipeline using AWS and Open Source Frameworks – A Case Study
The client is a top American company specialized in the use of marketing to sell home care, health and beauty products. The company’s global data platform has a legacy data warehouse to store various marketing data for generating BI reports.
The Challenge
The company is seeking to implement a new cloud-based data lake, enterprise data warehouse and data pipeline process that leverages both the AWS suite of services as well as other complementary tools to address the rapid growth of data originating from various dynamic sources.
How Auxenta Helped
Auxenta cloud team was part of the core engineering team, which designed the following baseline data platform modules in the cloud:
The Solution
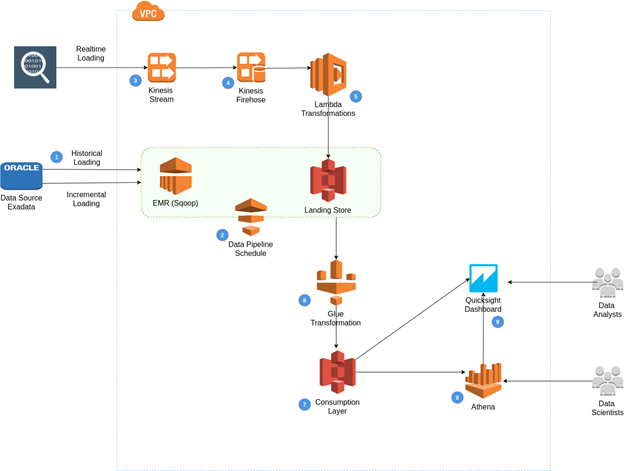
The proposed solution enables historical, incremental and real-time data ingestion to the data lake which is built on top of S3 object store. Data transformation jobs utilize Apache Spark framework atop AWS EMR clusters. Data reconciliation and lineage was facilitated via AWS platform.
Data ingestion method to the data lake depends on the volume and velocity of data in the datasource. (1) The initial data load for the historical data, originating from various on-premise databases will be performed using Apache Sqoop on a EMR cluster. (2) AWS Data Pipeline will orchestrate the load process.
AWS Kinesis Stream (3) coupled with AWS Kinesis Firehose (4) will be used to capture rapid realtime data (Eg: click stream data) into the Data lake. Data coming into Firehose will be be processed using lambda functions (5) before the data get stored on S3.
Once the data reached the landing store, pre configured Glue jobs (6) will be triggered to run data transformation jobs written in PySpark framework. The transformation results get stored in the data consumption layer (7) of the data lake in more optimized formats (Eg: Parquet, Orc, etc..) so that ad-hoc queries can be run via tools like AWS Athena (8). It will be AWS Glue’s job to create metadata catalog of the data in S3. Finally reporting tools like AWS QuickSight (9) can be used to generate BI reports, connecting to Athena and other connectors to slice and dice data by data analysts and data scientists.
Benefits to the client

Thilanka Liyanarachchi
Senior Software EngineerDeveloping a Custom Audit Trail and a Notification Service for a Workflow Based Serverless Application on AWS
READ ARTICLE
Human Emotions Recognition through Facial Expressions and Sentiment Analysis for Emotionally Aware Deep Learning Models
READ ARTICLE