Implementing an Enterprise Data Lake using AWS – A Case Study
One of the leading independent investment management companies was seeking to implement a cloud-based Enterprise Data Lake (EDL), an Enterprise Data Warehouse (EDW) and an Enterprise Data Pipeline (EDP) that leverage both the AWS services as well as other complimentary open source tools in the market.
Challenge
The company was seeking assistance in reviewing necessary data pipeline and end-user requirements and formulating a solution architecture as a Proof Of Concept (POC) for the current client reporting solution.
How Auxenta Helped
The Auxenta cloud team was part of the core engineering team, which designed the following baseline data platform modules in the cloud.
- 1. Ingestion
- 2. Transformation
- 3. Data access and consumption
- 4. Telemetry
Technologies Used
Amazon S3, AWS EMR, AWS Step Functions, AWS Lambda Function, Amazon Redshift, AWS API Gateway, Amazon Redshift Spectrum, Amazon SNS, Quicksight, AWS ElastiCache, AWS ElasticSearch, Apache Parquet, Kibana
The Solution
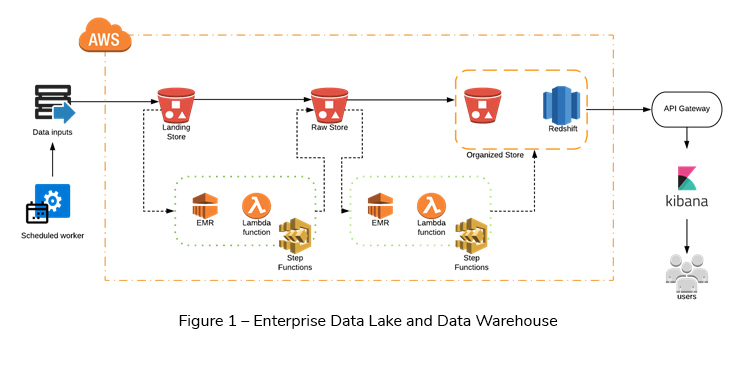
The solution can be explained using the following steps (See Figure 1).
1. Data Ingestion
The external scheduler pushes files to the Landing Store (S3) in the EDL. Then these files are arranged into appropriate folders within the Landing Store based on the file content.
2. Landing Store to Raw Store
An AWS Lambda function is triggered in the Landing S3 bucket whenever a files is pushed into it.
The files which are in the Landing Store go through some data validation, while they are being transferred to the Raw store (S3). Typically, these validation rules are stored in DynamoDB and the AWS Step Function is used to orchestrate this process. The processing of rules is carried out by the AWS Lambda/EMR depending on what the best fit is for each type of rules processing.
While in the data validation, any errors or invalid records are sent to an SNS topic. The valid records are converted to the “parquet” format before storing them in the Raw Store.
3. Raw Store to Organized Store
Similar to the Landing store, a separate Lambda function is configured in the Raw Store, which will be triggered whenever a file is pushed to the Raw Store as “parquet” format.
While transfering data from the Raw Store to the Organized Store (S3 or Redshift), the data is transformed/validated using an ETL process.
The Organized Store can be an Amazon Redshift or Amazon S3. The most recent and frequently used data is stored in Amazon Redshift and less frequently and older data are stored in S3. Finally the Redshift Spectrum is used to query the Organized Store.
4. The Data Access Layer
The Amazon API Gateway is leveraged to create, publish, maintain, monitor and manage data, which is stored inside the EDL. The business logic resides as Lambda functions and is mostly cached via Amazon ElastiCache.
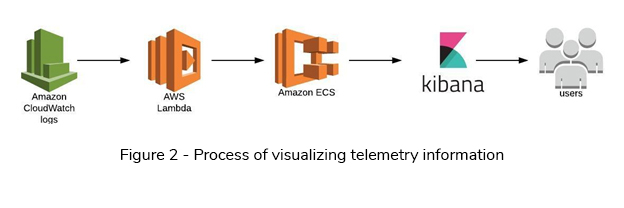
5. Telemetry
The AWS Cloudwatch collects logs from different AWS services in the EDL platform. Lambda is configured to collect data from CloudWatch logs and to send/index to the AWS Elasticsearch service. Kibana is used to visualize and search the telemetry data, which are indexed in Elasticsearch to gain operational insights (See Figure 2).
Benefits to the the client

Supun Bandara
Associate Tech LeadDeveloping a Custom Audit Trail and a Notification Service for a Workflow Based Serverless Application on AWS
READ ARTICLE
Human Emotions Recognition through Facial Expressions and Sentiment Analysis for Emotionally Aware Deep Learning Models
READ ARTICLE